

What is an LLM, Really? How they Work & How to Work with Them
The Complete Guide to Understanding Large-Language Models and How to Work with Them.


Have you ever wondered how a chatbot like ChatGPT or any other Large Language Model (LLM) works?
When a new technology really wows and gets us excited, it becomes a part of us. We make it ours, and we anthropomorphize it. We project human-like qualities onto it, and this can hold us back from really understanding how we are actually dealing with it.
So let's consider a few questions. Mainly, what is an LLM, and what are its limitations?
Perhaps these questions and ideas will illuminate our understanding:
Are LLMs a program?
Are LLMs a knowledge base? Do they tap into a Database of information?
Do LLMs know anything?
Many of us would assume ‘Yes’ to a few of these questions, but when we dig deeper, the ‘Yes’ starts to fall apart.
Consider the following:
If an LLM is a program, how does it compute its 70–100 billion parameters in only a few seconds?
If an LLM is a knowledge base, why does it need to predict? Why is there a confidence score?
How can an LLM model with billions of parameters that has been trained on pretty much the entire internet fit on a 100GB drive?
Now the picture is starting to become more clear. Hopefully, these questions dispel some of the mystique and confusion around LLMs.
There are a number of things that most people believe about LLMs that are contradictory and wrong.
First, LLMS are not knowledge bases, and they are not really programs either. What they are is a statistical representation of knowledge bases.
In other words, an LLM like ChatGPT4 has been trained on hundreds of billions of parameters that it has condensed into statistical patterns. It doesn't have any knowledge, but it has patterns of knowledge.
When you ask it a question, it predicts the answer based on its statistical model.
How do LLMs Work?
LLMs condense knowledge into patterns, and this includes words, phrases, and sentences and how they are related to each other.
Let’s look at a simple example. Imagine that you are in this living room.

This room has objects like a TV, sofa, coffee table, and other furniture. These objects have qualities like shape, color, type, function, etc., which can all be described in words.
Imagine that each of these objects was reduced down to words that described it within this 3D space. For example, the sofa would be described as being white, soft, comfortable, made with linen and cotton, having springs, made for sitting, and so on. If you asked, ‘Where can I sit?’ then all of the items that have the function of sitting would come up as an answer.
In simple terms, this is how LLMs are organized and function.
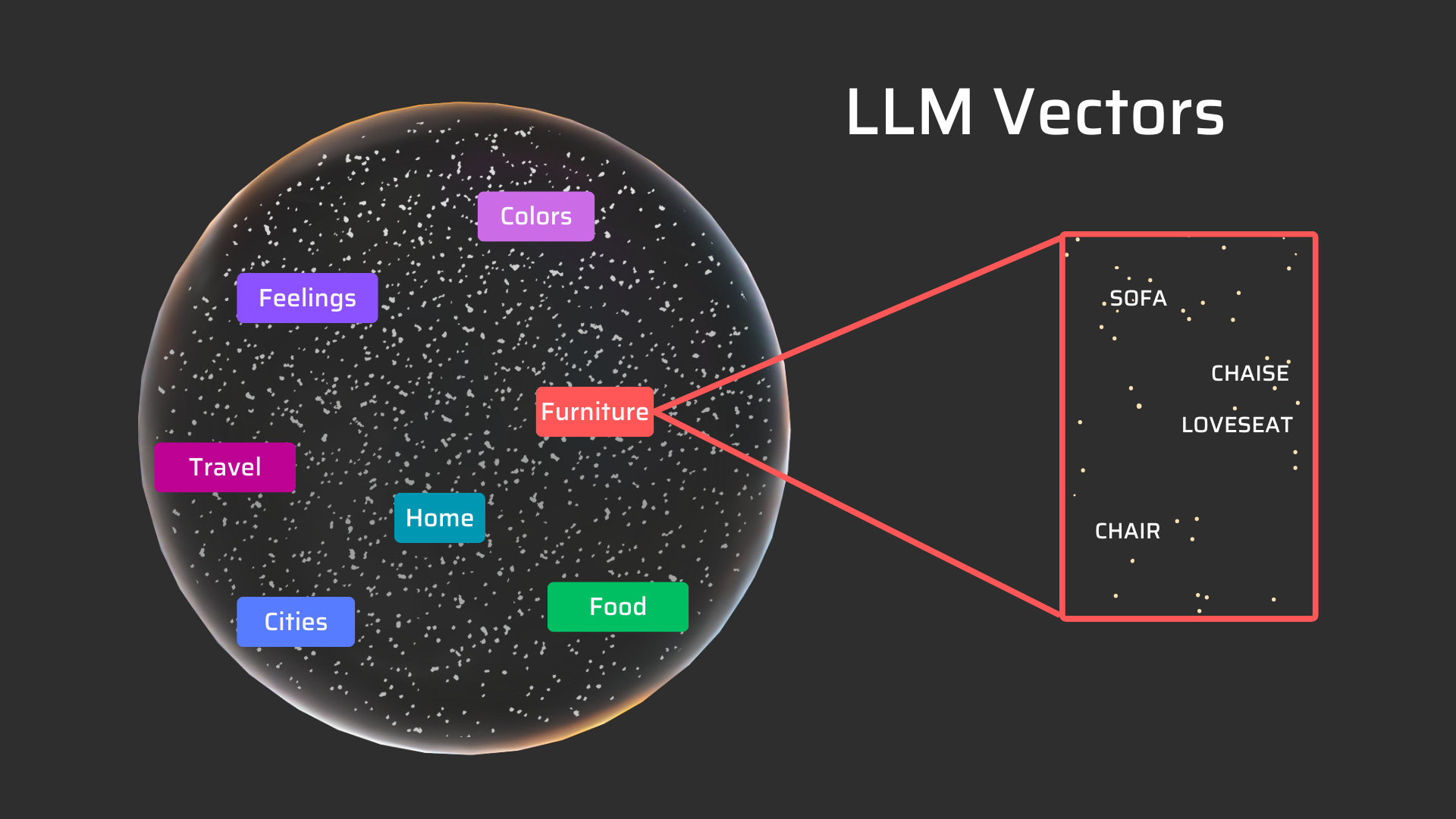
They use language and semantics to get to the core of meaning (eg: the sofa) and represent these words, phases, and sentences mathematically, as vectors, in a multi-dimensional structure.
When you ask an LLM a question, your question is turned into a sequence of tokens. Each token corresponds to a unit of text, which can be a word or a subword (e.g., "word" can be tokenized into "wo" and "rd"). These tokens are then fed into an LLM.
Once the LLM processes these tokens, it produces output in the form of vectors. These vectors represent the meaning or context of the input tokens in a multi-dimensional space. So, the input is in the form of tokens, and the output is represented as vectors.
Vectors & Embeddings
Here is how it breaks down:
In LLMs, words, phrases, and sentences are represented as dense vector embeddings. Each word or token is mapped to a high-dimensional vector.
Like our 3D environment, where objects are 3D space, imagine instead words being in this type of space.
These vector embeddings capture semantic relationships and contextual information. Words with similar meanings or usage have vectors that are closer together in the vector space.
Like in our living room example, a sofa, loveseat, and chaise are all objects you can sit on, so they will share a similar function and be tied to each other. Conversely, a word like ‘New York City’ would be very far from a sofa because these words are very different.
LLMs use these vector embeddings for various natural language understanding and generation tasks, including text completion, language translation, question answering, and chatbot interactions.
The primary goal of LLMs is to understand and generate human language, enabling them to perform language-related tasks with a focus on natural language processing (NLP).
Why do Good Models do Bad Things?
Why do good models do bad things? The answer lies in the models and how they are built.
LLMs are statistical representations of knowledge bases. They have taken the world's information and knowledge and boiled it down to statistical principles.
These principles are like icons. Icons represent something much more than what they are. They are low-resolution images that represent a much bigger chunk of information. They give you a lot more information than meets the eye.
This is how so much information can be stored on 100GB or even as little as 5GB!
And this is the paradox of LLMs. On one hand, they are so profound because of the relationships in their vectors, which allow them to answer a large breadth of questions.
On the other end of the spectrum, they often lack detailed information about the specifics, and this is where the predictions fall apart. Instead of knowing what they don’t know, they often predict what the most likely answer is, leading to ‘Hallucination’.
What are the Challenges and Limitations of LLMs?
LLMs were trained on biased data. We know this because the internet is full of biased data. For example, most of the internet is in English and represents Western values, yet the global population doesn't speak mostly English or hold Western values.
This was acknowledged by Sam Altman when he spoke at Davos. In that interview, he stated AI products will need to allow "quite a lot of individual customization" and "that's going to make a lot of people uncomfortable," because AI will give different answers for different users, based on their values and preferences and possibly on what country they reside in.
What is Bias?
What is bias? Is it ever a good thing? It's very important that we are on the same page of what it means so we can understand it better.
Here is the Webster definition of Bias:
an inclination of temperament or outlook, especially a personal and sometimes unreasoned judgment: PREJUDICE
an instance of such prejudice
deviation of the expected value of a statistical estimate from the quantity it estimates And/OR systematic error introduced into sampling or testing by selecting or encouraging one outcome or answer over others
Transitive verb
to give a settled and often prejudiced outlook to his background, which biases him against foreigners
to apply a slight negative or positive voltage to something, such as a transistor.
The most important insight here is that bias has its roots in our preferences. For example, if you prefer coffee over tea, you are more likely to show bias towards coffee. You might believe that more people drink coffee, that coffee increases your mental focus better, even that it is healthier. At the bare minimum, you will have more information about coffee, which will skew how you view both coffee and tea.
How does Bias Form?
Every interaction has three components. For example, as you read this sentence, there are the words on the screen, you, the reader, and the meaning you are gathering from this information.
The first stage is attention; you are paying attention to this instead of something else. The second aspect is your perspective. You are seeing these ideas from a point of view that is limited in time and space.
Consider how different this perspective would be if you read this essay five years ago.
Lastly, there is mean-making. All of these words will mean something to you. Depending on your background and education, consider how differently an engineer, a linguist, and a conversational designer would interpret this paragraph.
How does Bias form?
To properly address BIAS, we need to be aware of it at every stage of the process.
Attention: The world has too much information. Based on what we value, we decide where to look and what facts to pay attention to a priori.
BIAS: By doing so, we are implying that some information is more important than other information. We are showing a preference.
Perspective: We only see objects from a point of view. Our perspective skews how we see the things we are paying attention to.
BIAS: Seeing a limited perspective or only one side of an object, event, person, topic, we are leaving out the majority of the information, and this leaves us open to confirmation bias, selection bias, sampling bias, reporting bias, volunteer bias, publication bias, etc.
Meaning-making: We turn limited data on limited things into meaning. Making decisions is a process that involves our identities, beliefs, culture, personalities, etc. For example, consider how an adult and a child would interpret a similar event.
BIAS: The entire knowledge base is a construct, something we fabricate. It’s a useful invention that doesn't exist outside of us.
How to Overcome LLM Limitations
There are a number of things we can do to mitigate the risks of bias, hallucination, and poor accuracy. These solutions are becoming more and more common and they tend to be pretty effecting.
In future articles, I will go more deeply into each of these strategies.
Prompt Design, Engineering, and Tunning:
Bad questions and prompts will lead to bad answers! Consider ways to design your prompts so that they are not biased, that they are open-ended, and that you are referencing very specific facts within the model.
In our Personality NFT Project, getting the right answers about personality depends on understanding the different frameworks, tests, and research. We then reference the theories and models that have a strong scientific foundation so as not to confuse the model with other frameworks that are popular within our culture but scientifically valid.
Knowledge Bases
LLMs won’t know all of the details about your business or project. Creating a Knowledge Base is a great way to feed it your own data and make it easy for uses to ask your bot questions and get answers.
To increase the odds that the bot will answer correctly you need to design and organize the information in your knowledge base so that the LLM will gain the correct vector representations within the document parts.
There are a number of variables to consider, such as ontologies, taxonomies, and semantics. There is a connection between the Hierarchical Structure, the Marco context, the micro context, tagging, and words matter.
Flows & NLU
When you need to take the user down a specific path and don’t want to have control over what an AI Agent says, you can leverage conversational flows and NLU. In this way, you can take the user down a ‘happy path’, answer specific questions exactly as you intended, and use the LLM and Knowledge Bases to answer less critical questions and to engage the user.
Join the Journey
Join me as I journey and navigate through these waters.
Over the next few weeks and months I will be share my insights on AI, Philosophy, and the results on my experiments in implementing the best versions of these technologies.